Chcete rychle převádět zvuk z různých zdrojů na text a odstranit tak například bariéry v komunikaci? Tento článek vám ukáže, jak na to. Společně s námi si vytvoříte demo, které bude schopné vaši nahrávku převést na text a zjednodušit vám tak spoustu práce.
Jak vypadá finální výsledek?
Chcete-li se podívat, jak bude vypadat výsledek ještě než se vlastně pustíme do postupu, najdete ho zde. Máte zde připravené vše na vyzkoušení práce s umělou inteligencí a nepotřebujete k tomu ani jeden řádek kódu. Pokud ale chcete víc, než si jen něco vyzkoušet, ale i sami vytvořit, pokračujte s námi.
O projektu
Tento projekt vzniká v režii dvou studentů z Microsoft Studenského Trenérského Centra Anny Bicanové a Filipa Troníčka. Tento článek není zdaleka jediný, který v rámci tohoto projektu vyjde zde na blogu studuj.digital, proto se můžete těšit i na další. Jeden už dokonce najdete zde. V tomto článku se budeme zabývat službou Speech to Text v Azure a budeme ji demonstrovat v praxi.
Doporučujeme si před začátkem přečíst i tento článek, který vám představí službu Speech to Text ještě předtím, než ji uvedete do praxe.
Co budeme potřebovat?
Azure
K tomuto projektu budete potřebovat nějakou licenci na Azure. My používáme Azure for Students. Jak aktivovat tuto licenci si přečtěte zde:
Visual Studio Code
Abyste se mohli pustit do tohoto projektu, budete potřebovat nějaký textový editor. Doporučujeme Visual Studio Code. Ten najdete zdarma ke stažení na code.visualstudio.com a podrobný návod k instalaci si můžete projít zde:
API klíče z Azure Portálu
Postup k jejich získání si ukážeme v následujícím kroku.
Jdeme na to!
Azure API klíče:
Jako první si musíme vygenerovat API klíče (aplikační programovací rozhraní).
- Přesuneme se na Microsoft Azure Portal, kde vyhledáme pojem „Speech to Text“.
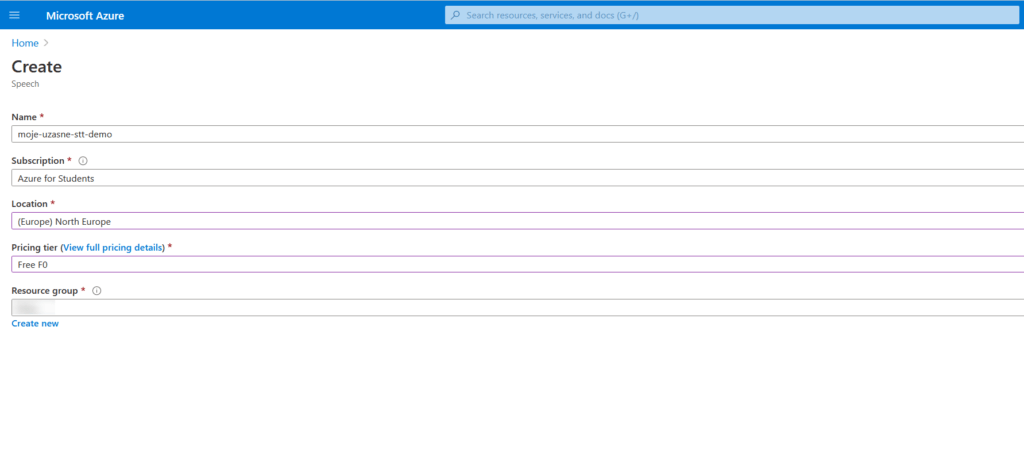
- Poté v sekci „Marketplace“ klikneme na „Speech to Text“ a vyplníme formulář, kde vybereme „Create new“. Jako lokaci vybereme tu nejbližší k nám – tou je „(Europe) North Europe“. Jako pricing tier vybereme F0 a resource group si vytvoříme novou.
- Chvíli počkáme, než se nám projekt vytvoří.
- Jakmile se nám projekt vytvoří, vybereme „Go to Resource“.
- Na boční liště klikneme na „Keys and Endpoint“.
- Klikneme na „Show Keys“ a zkopírujeme první z nich.

Kód
Prvně si vytvoříme složku na náš projekt a tu si otevřeme ve VS Code. Zde vytvoříme položku index.html, ve kterém bude struktura našeho webového projektu.
Nejprve si vytvoříme hlavičku. Zde nastavíme titulek stránky a importujeme naše skripty a styly.
<!DOCTYPE html>
<html lang="cs">
<head>
<title>Rozpoznání řeči</title>
<meta charset="utf-8" />
<link rel="stylesheet" href="https://unpkg.com/mvp.css" />
<link rel="stylesheet" href="style.css" />
<!-- Speech SDK -->
<script
src="js/sdk.js"
defer
></script>
<script src="js/process.js" defer></script>
</head>
V body našeho HTML vytvoříme tabulku s řádky:
- klíč – <input> pro API klíč
- region – <input> pro region služby
- tlačítko nahrát – <button> s id startRecognizeOnceAsyncButton (budeme ho hledat v JavaScriptu)
- výsledek nahrávání – <textarea> s id phraseDiv
<body>
<main>
<div id="content" style="display: none;">
<table width="100%">
<tr>
<td>
<h1 style="font-weight: 500;">
Rozpoznání řeci pomocí Azure Speech to Text
</h1>
</td>
</tr>
<tr>
<td align="right">Subscription klíč:</td>
<td><input id="subscriptionKey" type="text" size="40" /></td>
</tr>
<tr>
<td align="right">
Zvolený region (neměňte, pokud nevíte, co děláte)
</td>
<td>
<input id="serviceRegion" type="text" size="40" value="northeurope" />
</td>
</tr>
<tr>
<td></td>
<td>
<button id="startRecognizeOnceAsyncButton">
Začít nahrávání
</button>
</td>
</tr>
<tr>
<td align="right" valign="top">Výsledek</td>
<td><textarea id="phraseDiv"></textarea></td>
</tr>
</table>
</div>
</main>
</body>
</html>
To by mělo vypadat cca takto:
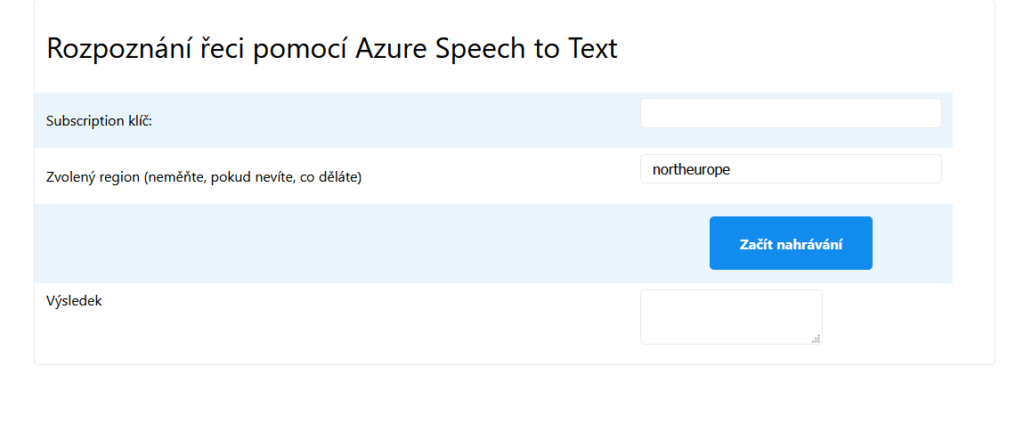
Teď to půjdeme ještě nějak nastylovat, ať jsou prvky trochu více konzistentní.
Vytvoříme soubor style.css, do kterého přidáme následující styly:
body {
font-family: 'Helvetica Neue', Helvetica, Arial, sans-serif; /* Nastavíme font, který chceme použít */
font-size: 13px;
}
#phraseDiv {
/* Změníme dimenze našeho textarea inputu */
display: inline-block;
width: 820px;
height: 200px;
max-width: 100%;
}
td {
max-width: 26vw;
}
Po malých úpravách bude projekt vypadat asi takto:
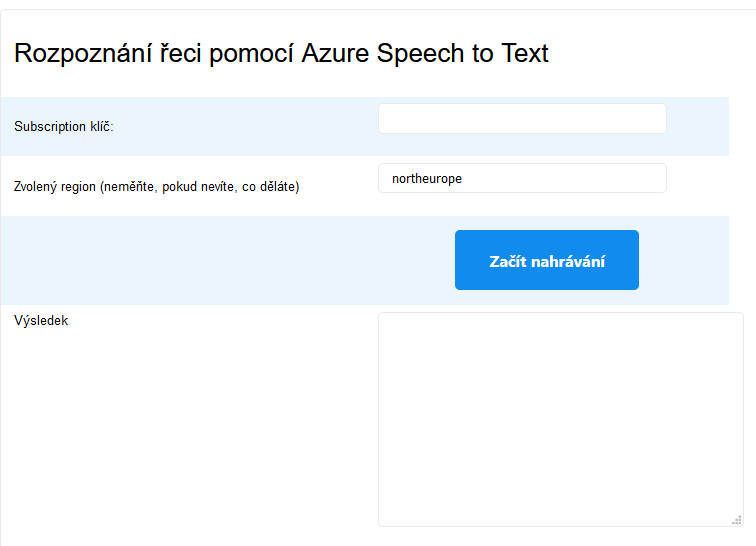
Poté si vytvoříme složku js a v ní soubor sdk.js, do kterého vložíme skript z GitHubu.
Jako poslední součást našeho programu bude skript process.js, který vytvoříme také ve složce js.
Na začátku souboru referujeme naše HTML prvky a uložíme si je do proměnných.
const startRecognizeOnceAsyncButton = document.getElementById(
"startRecognizeOnceAsyncButton"
);
const subscriptionKey = document.getElementById("subscriptionKey");
const serviceRegion = document.getElementById("serviceRegion");
const phraseDiv = document.getElementById("phraseDiv");
Poté si předdefinujeme proměnné pro autorizační token, SDK pro komunikaci s API a poté ještě náš hlasový recognizer.
let authorizationToken;
let SpeechSDK;
let recognizer;
Následně vytvoříme funkci, která bude zavolána po načtení celého DOMu.
document.addEventListener("DOMContentLoaded", () => {
// Tady bude náš kód
})
Vytvoříme funkci, jejíž kód bude proveden po stisknutí nahrávacího tlačítka.
startRecognizeOnceAsyncButton.addEventListener("click", () => {
})
Prvně nastavíme, že se tlačítko zešediví a nepůjde s ním nijak interagovat a sekce výsledku se promaže.
startRecognizeOnceAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
Dále definujeme proměnnou na konfiguraci. Dále do ní zapíšeme konfiguraci z tokenu.
// if we got an authorization token, use the token. Otherwise use the provided subscription key
let speechConfig;
if (authorizationToken) {
speechConfig = SpeechSDK.SpeechConfig.fromAuthorizationToken(
authorizationToken,
serviceRegion.value
);
} else {
if (
subscriptionKey.value === "" ||
subscriptionKey.value === "subscription"
) {
alert("Zadejte klíč!");
startRecognizeOnceAsyncButton.disabled = false;
return;
}
speechConfig = SpeechSDK.SpeechConfig.fromSubscription(
subscriptionKey.value,
serviceRegion.value
);
}
Nastavíme jazyk nahrávání a metodu – budeme nahrávat naším mikrofonem.
speechConfig.speechRecognitionLanguage = "en-US";
const audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
recognizer = new SpeechSDK.SpeechRecognizer(speechConfig, audioConfig);
Teď nastavíme metodou SDK recognizeAsync hodnotu pole výsledku na text, který nám vrátí. Pokud se to nepovede, vepíšeme to do konzole.
recognizer.recognizeOnceAsync(
(result) => {
startRecognizeOnceAsyncButton.disabled = false;
phraseDiv.value = result.privText;
recognizer.close();
recognizer = undefined;
},
(err) => {
startRecognizeOnceAsyncButton.disabled = false;
phraseDiv.value = err;
console.error(err);
recognizer.close();
recognizer = undefined;
}
);
Nakonec (již venku z .addEventListener funkce) načteme SDK a pokud úspěšně, tak schováme naše upozornění o chybějícím SDK souboru.
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startRecognizeOnceAsyncButton.disabled = false;
document.getElementById("content").style.display = "block";
document.getElementById("warning").style.display = "none";
// in case we have a function for getting an authorization token, call it.
if (typeof RequestAuthorizationToken === "function")
RequestAuthorizationToken();
}
Závěr
Doufáme, že se vám podle našeho návodu podařilo udělat podobné demo jako jsme vytvořili my. Pokud jste z kódu něco nezachytili, je dostupný na GitHubu.