Předmětem předešlého článku bylo představení naší aplikace a využití služby Custom Vision pro detekci objektů. Zde se hlouběji ponoříme do kódu naší aplikace a ukážeme si klíčové části, které se vám při tvorbě podobné aplikace mohou hodit – implementace exportovaného modelu, tvorba boxů kolem objektů a práce s frameworkem Flask.
Obsah
Požadavky
- Přečtení úvodu ke Custom Vision a 1. dílu tohoto článku
- Nainstalovaný Python 3.x (článek o instalaci Python)
- Základní znalosti programování a HTML
Instalace nezbytných balíčků
Námi zvolený exportovaný model používá jeden z nejznámějších frameworků pro hluboké učení tensorflow. Výhodný je pro nás především kvůli tomu, že takto exportovaný model je napsán v jazyku Python. Ten používá také framework pro tvorbu webových aplikací Flask, jenž využijeme na serveru aplikace. Zmíněné balíčky spolu s pár dalšími nainstalujeme v konzoli pomocí pip.
pip install tensorflow
pip install flask
pip install Pillow
pip install numpyFlask
Předností Flasku je především jeho jednoduchost. Jako první vytvoříme soubor applicaiton.py a uvnitř instanci Flask aplikace.
import flask
app = Flask(__name__)
Na konec souboru musíme ještě umístit podmínku, která bude aplikaci spouštět.
if __name__ == '__main__':
app.run()
Mezi ně teď můžeme definovat routes – cesty, pomocí kterých můžeme v aplikaci uživatele přesměrovat. Každá z nich pak dokáže vykonávat jiný účel. Jako první musíme definovat základní cestu, jejíž instrukce se vykonají při příchodu uživatele na stránku.
@app.route('/'):
def home():
...
return render_template('index.html') #vykreslí html dokument
Poslední důležitá věc, která musí zaznít, je fakt, že Flask požaduje pevně danou strukturu složek.
- /templates – html soubory
- /static/css – css soubory
- /static/img – obrázky
To bylo to nejpodstatnější, co budeme pro tento projekt potřebovat. Do budoucna se vám může hodit detailní dokumentace Flasku v angličtině. Teď se pojďme podívat, jak lze Flasku předat data uživatele.
Odeslání dat
V duchu dodržení rozumné délky tohoto článku se zde nebudu věnovat tomu, jakým způsobem používat na stránce webkameru tak, jak to dělá stránka naše. Jedná se jen o jeden z mnoha způsobů, jak snímek od uživatele získat. Pokud by vás tato nebo kterákoli jiná nezmíněná část aplikace zajímala, najdete kompletní okomentovaný kód na našem GitHubu.
Jako nejjednodušší metoda předání dat se nabízí odeslání přes formulář.
<form action="/detect" method="POST" id="send">
<input type="hidden" id="image" name="image"> </form>
Atribut action říká, kam bude uživatel po odeslání přesměrován. V našem případě to bude bude route, kterou jsme si definovali v backendu aplikace. Další atribut method pak definuje, jestli chceme data odeslat – „POST“ nebo přijmout – „GET“.
Form pak můžeme odeslat v HTML přidáním tlačítka:
<button type="submit" form="send" value="image">Submit</button>
Pokud potřebujete před odesláním provést nějakou formu logiky nebo úpravu dat, nabízí se odeslání přes JavaScript. V případě naší aplikace je náš snímek uložen jako prvek canvas. Ten jako takový odeslat nejde, proto ho v JavaScriptu upravíme na vhodný formát a formulář odešleme přes něj. Nejdříve si vyžádáme potřebné prvky podle jejich id.
<script>
const inputImage = document.getElementById('image');
const formImage = document.getElementById('send');
const submit = document.getElementById('submit'); //element tlačítka
Abychom canvas mohli odeslat na server, musíme ho převést na informaci ve formátu base64, který převádí binární informaci na řetězec znaků. Tuto informaci přiřadíme prvku input uvnitř formuláře a odešleme.
submit.addEventListener("click", function(){ //událost se zavolá po stisknutí tlačítka
var dataURL = canvas.toDataURL(); //převede data
inputImage.value = dataURL; //převedená data přiřadíme
formImage.submit(); }); //odešle vyplněný form
Přijmutí dat
Poté, co server přijme snímek v podobě řetězce, musíme nejprve odříznout metadata – zprávu popisující druh informace. Následně musíme dekódovat nazpět náš snímek tak, aby bylo možné s ním dále pracovat.
@app.route("/detect", methods=['POST', 'GET']) #methods říká jestli cheme data přijímat nebo odesílat
def detection():
if request.method == 'POST':
image_b64 = request.values['image'] #vyžádání obrázku z html form jako base64 data
image_b64 = re.sub('^data:image/.+;base64,', '', image_b64)#nahradí metadata prazdným řetězcem
image_data = BytesIO(base64.b64decode(image_b64)) #dekódovaní base64 dat
Poté můžeme snímek otevřít v modulu Pillow (PIL), jenž nabízí jednoduchou práci s obrázky.
image = Image.open(image_data)
Budeme ho používat i při vykreslovaní boxů kolem detekovaných objektů. Předtím ale musíme použít náš exportovaný model k získání predikcí o našem snímku.
Práce s exportovaným modelem
Po exportování a následném extrahování .zip souboru uvidíme následující soubory:
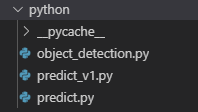
Soubor object_detection.py obsahuje definici třídy ObjectDetection, kterou dále používají funkce v predict.py k detekci a generování nejpravděpodobnějších značek uvedených v labels.txt. Soubor predict_v1.py je funkčně totožný s predict.py, ale je určen pro starší verze tensorflow 1.x. Proto ho můžeme smazat. Pokud vás zajímá podrobný rozbor toho, co se v souborech děje, najdete ho v tomto článku. Nám ale bude stačit funkce main ze souboru predict.py.
import sys #přidá složku python k prohledávaným složkám sys.path.insert(1, python) from predict import main
Ta jako svůj parametr přijme náš snímek a vrátí nám predikce v podobě „seznamu“ (list) „slovníků“ (dictionaries).
image = Image.open(image_data)
predictions = main(image_data)
print("predictions: ", predictions)
"""
predictions: [{'probability': 0.12775692,
'tagId': 0,
'tagName': 'Lightning',
'boundingBox': {'left': 0.29989651, 'top': 0.65226842, 'width':
0.3119592, 'height': 0.37785795}}]
"""
Abychom se dostali k určité hodnotě, musíme specifikovat pořadí detekovaného objektu, jehož je hodnota součástí a klíč hodnoty je: predictions[0]['tagId']
Nyní máme všechny potřebné informace k vykreslení boxů kolem objektů, které model detekoval.
Vykreslování boxů
Jako souřadnice pro nakreslení obdélníku nám poslouží hodnoty ve vnořeném slovníku s klíčem 'boundingBox'.
'left'/'top'– vzdálenost levého horního rohu od levého / horního kraje snímku'width'/'height'– šířka / výška boxu
Ty jsou vyjádřeny v procentuálním poměru k rozměrům původního snímku. Abychom dostali jejich absolutní hodnoty, musíme vynásobit hodnoty ‚left‘ a ‚width‘ šířkou a ‚top‘ a ‚height‘ výškou snímku.
Pro vykreslení použijeme modul ImageDraw, který je stejně jako Image součástí modulu Pillow. Ten pak nabízí metodu rectangle, která přijímá jako souřadnice dvojici bodů (x0, y0) – levý horní roh a (x1, y1) – pravý dolní roh. Následně přidáme popisek s názvem předpokládaného objektu. Stejnou proceduru zopakujeme pro každý objekt v seznamu.
from PIL import ImageDraw
def draw_boxes(image, predictions):
img_width, img_height = image.size #předání šířky výšky
img = ImageDraw.Draw(image)
for obj in predictions:
#výpočet souřadnic
x0 = obj['boundingBox']['left'] * img_width #horní levý roh
y0 = obj['boundingBox']['top'] * img_height
x1 = x0 + (obj['boundingBox']['width'] * img_width) #dolní pravý roh
y1 = y0 + (obj['boundingBox']['height'] * img_height)
shape = [(x0, y0), (x1, y1)]
img.rectangle(shape, outline ="red") #nakreslí box
img.text((x0 + 10, y0 + 10), obj['tagName'], fill="red") #přidá popisek
return image

Upravený snímek uložíme a spolu s jmény dvou nejpravděpodobnějších portů pošleme na další stránku.
image = draw_boxes(image, predictions)
image = image.save(os.path.join(app.config['IMAGE_UPLOADS'], '{}.png'.format(predictions[0]['probability']))) #'probability' slouží jako unikatní jméno pro uložení.
return render_template('choice.html', user_image=os.path.join(app.config['IMAGE_UPLOADS'], '{}.png'.format(predictions[0]['probability']))
,port1=predictions[0]['tagName'], port2=predictions[1]['tagName'])
Práce s proměnnými
Jako příklad toho, jak následně pracovat s odeslanými proměnnými, jsem zvolil opět kousek kódu naší aplikace. Flask používá pro proměnné posílané ze serveru na straně HTML symboly „{{ }}“. Ty se po spuštění nahradí proměnnými specifikovanými uvnitř.
<img class= "img" src="{{user_image}}" alt="fotka s oznacenymi boxy" >
<input type="hidden" id="port1" value="{{port1}}">
<input type="hidden" id="port2" value="{{port2}}">
Když teď máme data uložena uvnitř prvků input, můžeme je v JavaScriptu spojit spolu s údajem o požadované délce kabelu zadaným uživatelem a vyhledat řetězec automaticky v prohlížeči.
const port1 = document.getElementById('port1');
const port2 = document.getElementById('port2');
const search_text = document.getElementById('search_text');
const search = document.getElementById('search');
search.addEventListener("click", function(){ searsearch.addEventListener("click", function(){
search_text.value = port1.value + " to " + port2.value + ' ' + length.value + "m";
window.open("https://www.bing.com/search?q="+search_text.value);
});
Závěr
Tímto článkem jsem se snažil vypíchnout to nejdůležitější, co by se mohlo při vytváření webové aplikace s modelem Custom Vision hodit. Mnohé jsem z důvodu délky článku vynechal, a proto znovu doporučuji navštívit GitHub našeho projektu, kde najdete kód kompletní. Další důležitá část vytváření webových aplikací, kterou jsem vynechal, je hostování. Ta naše využívá možnost nasazení z GitHubu přímo do služby Azure Web Apps. O tomto tématu už jeden článek na našem blogu vznikl, proto ho taktéž doporučuji navštívit.
Custom Vision spolu s ostatními kognitivními službami skýtá jistě velký potenciál, jak využít moderní AI systémy bez jakékoliv hluboké expertizy. Stačí tak mít jen ten správný nápad. Doufám, že vám článek posloužil jako návod, jak svůj nápad proměnit s pár řádky kódu v realitu.