

V předešlém díle relačních databází v Azure jsem vysvětloval, jak založit a zprovoznit službu Azure SQL Database. Při nastavování serveru pro vaší databázi je zde však jedna složitější část a to vybrání pricing modelu a jeho nastavení. Právě to si dnes vysvětlíme a ukážeme pricing SQL databáze.
Obsah
Technické znalosti a požadavky
- Počítačová sestava
- Internetové připojení
- Základní znalosti cloud computingu a Azure
- Základní znalosti databází SQL
- Aktivovaný účet Azure for Students nebo jiný
Přečtěte si předchozí díl série o tom, jak SQL databázi založit.
Pricing modely Azure SQL databáze
Vybrání správného pricing modelu a jeho nastavení je stěžejní, abyste mohli vaši databázi využívat efektivně. Microsoft používá pro toto nastavení 2 rozdílné sekce a to na DTU-based a vCore-based. Díky tomuto rozdělení může takový databázový server efektivně nastavit jak úplný nováček, tak profík v oboru. Obě sekce vám ukážeme a detailně vysvětlíme. Do nastavení vašeho serveru a vybrání pricing modelu se dostanete pomocí odkazu Configure database v sekci Basics > Database details > Compute + storage.
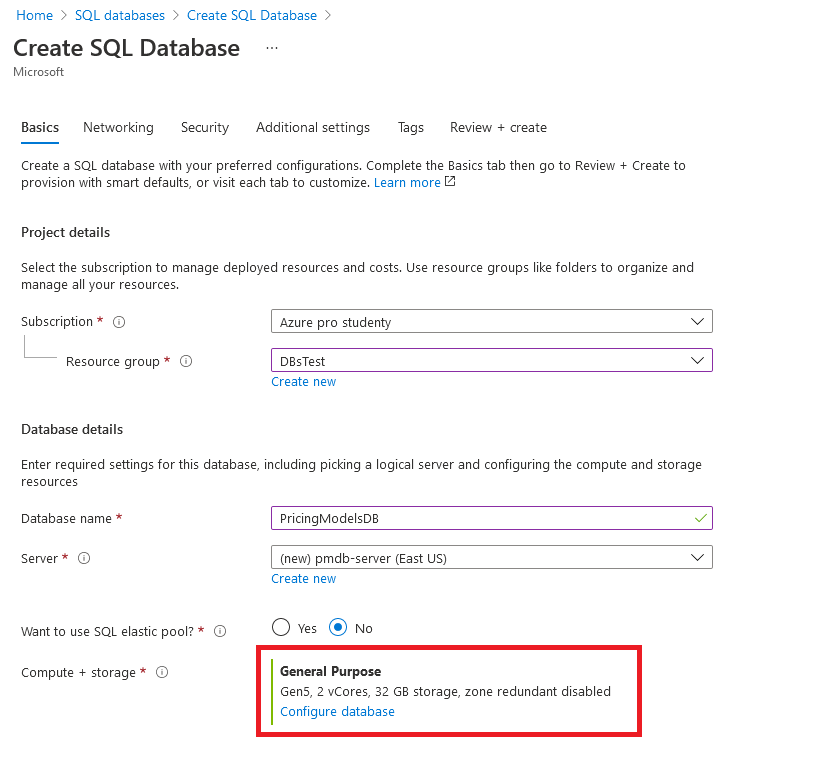
DTU-based model
Jak z názvu vyplývá, DTU-based model se točí kolem jednotky DTU – Data Transaction Unit. Tato jednotka reprezentuje přednastavenou kombinaci CPU, paměti a počet zápisů a čtení z databáze. Tato jednotka je předem nastavena tak, aby všechny zdroje byli v poměru, v jakém se obvykle používají v reálných případech. Díky tomu si stačí jednoduše nastavit počet těchto jednotek a k tomu nastavit velikost úložiště.
Vybrané zdroje zůstávají alokované celou dobu pouze vám, tudíž se za tento model platí fixní měsíční částkou, nehledě na to, jak moc vaší databázi budete využívat. Tento model je nejvhodnější pro ty, kteří nemají zkušenosti s nastavováním těchto strojů a nevyžadují nastavení každé části dle jejich vlastního uvážení. Nyní vám ukážu, jak vypadá nastavení tohoto modelu.
Nastavení modelu
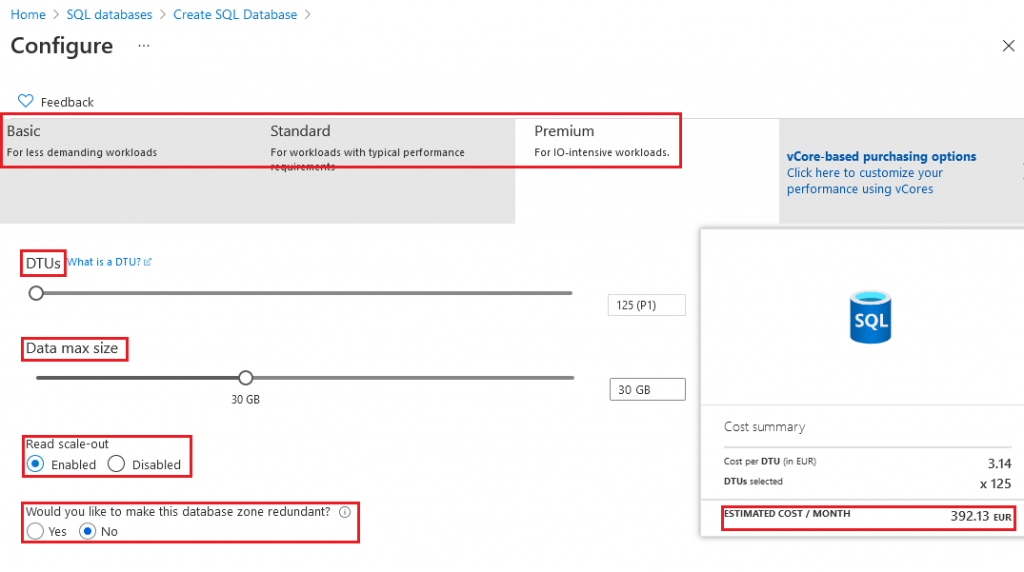
Hned nahoře se nachází první volba – zvolení úrovně tohoto modelu. Jsou zde na výběr tři – Basic, Standard a Premium. Pro málo používané nebo nedůležité databáze je vhodné zvolit nejslabší možnost, Basic. Pro velmi často používané a důležité databáze, kdy potřebujete mít velmi nízkou odezvu, je vhodné zvolit úroveň Premium. Standard je takový zlatý střed.
Po vybrání úrovně se vám zobrazí jedna, dvě nebo čtyři další možnosti, které můžete nastavit. V následující tabulce můžete vidět, které úrovně podporují tyto možnosti. x znázorňuje že tato funkce je v dané úrovni obsažena.
| Basic | Standard | Premium | |
| DTUs | X | X | X |
| Data max size | X | X | |
| Read scale-out | X | ||
| Redundacy | X |
Níže následují dva posuvníky. Jeden nese název DTUs a druhý Data max size. Posuvník DTUs slouží pro zadání počtu jednotek DTU pro váš server. Pomocí posuvníku Data max size zase nastavíte maximální velikost dat, které se v databázi budou nacházet.
Následují dvě poslední možnosti. Read scale-out a otázka, zda byste chtěli využít takzvaných Availability zón. Read scale-out je funkce, která automaticky využívá předalokovanou repliku vašeho serveru, která je díky tomu využita pro read-only připojení a dotazování bez jakéhokoli příplatku. Díky tomu můžete velmi dobře vyvažovat práci s těmito databázemi a rozložit práci mezi repliku a váš server. Jako poslední možnost je již zmíněné využití availability zón. Pokud zaškrtnete Yes, tak díky tomu vytvoříte repliky vašeho serveru v dalších data centrech, díky čemuž můžete zlepšit dostupnost vaší služby a předejít možným výpadkům ze strany Azure.
Jakmile si vše nastavíte, můžete vpravo vidět měsíční poplatek, který budete muset platit pro využití této služby.
TIP: Pokud přecházíte z lokální infrastruktury na Azure a chcete využít DTU-based modelu, ale nevíte kolik jednotek DTU budete potřebovat, můžete využít kalkulačky DTU
V-Core based model
Tento model je oproti předešlému o něco složitější. Jeho základní jednotkou jsou vCores (virtuální jádra) a reprezentují jednotlivé logické jednotky. Díky tomu, že si nastavujete rovnou počet jader, se zde nabízí větší flexibilita. V tomto modelu můžete nastavit například počet vCores, počet replik nebo dokonce hardware, na kterém to vše bude běžet. Rozdílný hardware má navíc poskytuje jiný počet možné paměti nebo virtuálních jader. Díky těmto možnostem si každý může nastavit svůj server přesně na míru. Nyní vám ukážu nastavení tohoto modelu.
Nastavení modelu

Ve vCore-based modelu máte na výběr tři úrovně. Každá se hodí na něco jiného a má k dispozici jiné prostředky a funkce. Tyto úrovně nesou názvy General Purpose, Hyperscale a Business Critical. Už díky tomuto rozdělní jde vidět rozdíl v obtížnosti nastavování tohoto modelu. Každou úroveň vám popíšu a vysvětlím každou jejich funkci.
General Purpose
Úroveň General Purpose je první úrovní vCore-based modelu, která je vám k dispozici. Tato úroveň nabízí cenově dostupnou rovnováhu mezi výkonem a úložištěm. Odezva serveru je mezi 5 a 10 milisekundami a IOPS (Input/Output Operations Per Second) je v rozmezí 500 až 20 000. Díky těmto vlastnostem je General Purpose ideální volbou do většiny projektů.
Tato úroveň má navíc ještě dva poddruhy a to Provisioned a Serverless. Oba fungují odlišně a hodí se do jiných projektů. Navíc mají lehce odlišné nastavení. Proto vám oba samozřejmě ukážu a popíšu.

Provisioned
Prvně se koukneme na druh Provisioned. Díky němu je váš výkon a vaše zdroje neustále k dispozici. Po nastavení počtu vCores platíte za každou hodinu, co jsou tato virtuální jádra nakonfigurována. Pokud byste chtěli váš výkon škálovat (navyšovat a redukovat v závislosti na využívání), musíte to dělat manuálně. Jádra zůstávají nakonfigurovaná a vám k dispozici, dokud vy neurčíte jinak. Tento druh se nejvíce hodí pro databáze, které jsou často používané, proto se vyplatí mít neustále k dispozici váš nastavený výkon. Nevýhodou však je, že platíte za vaše nakonfigurovaná jádra i přes to, že je momentálně nepoužíváte. Nyní vám ukážeme všechny možnosti nastavení, které tento druh nabízí.

Kolonka Save money je pro ty, kteří už mají licenci pro Microsoft SQL Server. Je to totiž databázový a analytický systém vyvíjený Microsoftem, který na těchto serverech běží. Abyste tento systém mohli používat, je zapotřebí vlastnit jeho licenci. Pokud ji již máte, tak toho můžete využít a zaškrtnout Yes.
Pomocí posuvníku vCores nastavujete jejich počet. Čím více jich nakonfigurujete, tím větší výkon bude váš server mít, ale tím více budete také platit. Pomocí druhého posuvníku Data max size nastavíte velikost úložiště pro váš server. Vpravo dole od tohoto posuvníku můžete vidět úložiště, které bude alokované čistě pro logy vaší databáze.
Poslední volba je stejná jako u DTU-modelu a to je využití Availability zón za účelem zlepšení dostupnosti a zálohování.
Serverless
Druhý poddruh z této dvojice je Serverless. Zde, na rozdíl od Provisioned, nemáte veškerý výkon neustále k dispozici. Výkon se škáluje automaticky podle jeho využívání. V nastavení si nakonfigurujete maximální a minimální počet vCores a v tomto rozmezí se budou pohybovat vaše momentální nakonfigurovaná jádra a společně s tím se bude měnit cena, jelikož za tento druh platíte za sekundu použitých vCores. Proto je vhodný pro databáze, ke kterým přistupujete nepravidelně. Nevýhoda tohoto modelu však spočívá v tom, že škálování jader nebo znovuspuštění pozastavené databáze prodlužuje odezvu, proto může být tato databáze pomalejší. Nyní se přesuňme na nastavení tohoto poddruhu.

Pomocí posuvníků Max vCores a Min vCores si můžete nastavit již zmíněné rozmezí, ve kterém se bude váš výkon pohybovat. S těmito posuvníky jde ruku v ruce hned další možnost a tou je Auto-pause delay. Pokud tuto možnost povolíte zaškrtnutím Enable auto-pause, bude celá vaše databáze, po uplynutí vámi specifikovaného času, automaticky pozastavena. Díky tomu nebudou žádná jádra nakonfigurovaná a nebudete za ně nic platit. Než váš zadaný čas uplyne, budete platit za minimální počet používaných jader, které jste si nastavili pomocí druhého posuvníku. Pro lepší pochopení se můžete podívat na následující obrázek:

Poslední dvě možnosti jsou opět Data max size a využití Availability zón. Obě možnosti jsem již vysvětloval v předešlých modulech.
Hyperscale
Úroveň Hyperscale je nejnovější úrovní, která je pro Azure SQL Database dostupná. Její výhodou je škálovatelnost. Zde si totiž nenastavujete velikost vaší databáze. Úložiště se automaticky škáluje podle uložených dat a tím můžete uchovávat až 100 TB dat, oproti 4 TB jako tomu je u General Purpose nebo Business Critical. Díky tomu nemusíte platit za žádné úložiště, které aktuálně nepoužíváte. Teď se znova přesuňme na jeho nastavení.
Upozornění: Jak jsme zmiňovali, úroveň Hyperscale je nejnovější ze všech, proto některé funkce mohou být zablokované nebo po jejich aktivování nevratné. Pro zjištění jejich momentálního stavu se můžete podívat do dokumentace této úrovně.
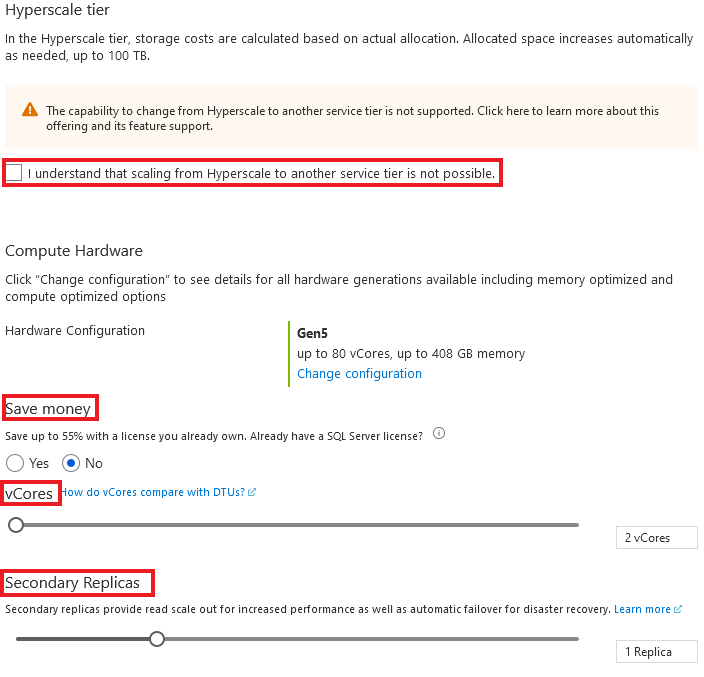
Hned první možností je jedno zaškrtávací políčko pod upozorněním. Po nastavení vaší databáze můžete upravovat její nastavení a měnit úrovně. U Hyperscale to tak zatím není. Pokud databázi vytvoříte pod úrovní Hyperscale, nebo na ní již existující databázi převedete, tak je tato akce nevratná a nebudete již moct vybrat úroveň jinou. Bez potvrzení, že jste si toho vědomi nebudete moct tuto databázi vytvořit.
Další dvě možnosti, Save money a vCores, jsem již vysvětloval u úrovní předešlých. Pomocí možnosti Save money můžete za server ušetřit, pokud již vlastníte licenci pro Microsoft SQL Server a pomocí posuvníku vCores nastavujete počet virtuálních jader.
Poslední možností je posuvník Secondary Replicas. Použití těchto replik je nápomocné hned z několika důvodů. Jedním z nich je takzvaný read-scale out, o kterém jsem psal již u DTU-based modelu. Díky read-scale out funkci, bude Azure používat repliky vaší databáze pouze pro čtení z nich. Díky tomu uvolníte výkon vaší hlavní databáze a ta se může věnovat komplexnějším operacím nebo zápisům. Další výhodou je, že pokud vaše hlavní databáze selže, tak se všechny vaše operace automaticky přesunou na jednu z dostupných replik.
Business Critical
Teď se pojďme něco naučit o poslední úrovni – Business Critical. Díky svému vysokému výkonu vám může nabídnout až 204 800 IOPS a odezvu do 2 milisekund. Těchto hodnot může dosáhnout pomocí své architektury. Základ této architektury spočívá v tom, že vaše databáze má neustále k dispozici nějaký výkon navíc, se kterým můžete pracovat. Toho se docílí pomocí replik výkonu a úložiště vaší databáze. Využívá se na to jeden hlavní uzel vaší databáze, ze které se vytvoří tři další vedlejší uzly (repliky). Hlavní uzel má na starost přepisy databáze a odeslání upravených dat dalším třem replikám. Využití těchto replik zahrnuje odpovídání na čtecí dotazy pro databázi a slouží jako náhrada za hlavní uzel – pokud hlavní uzel selže, jedna z replik se stane novým hlavním uzlem. Pro lepší pochopení této metody se můžete podívat na následující obrázek:
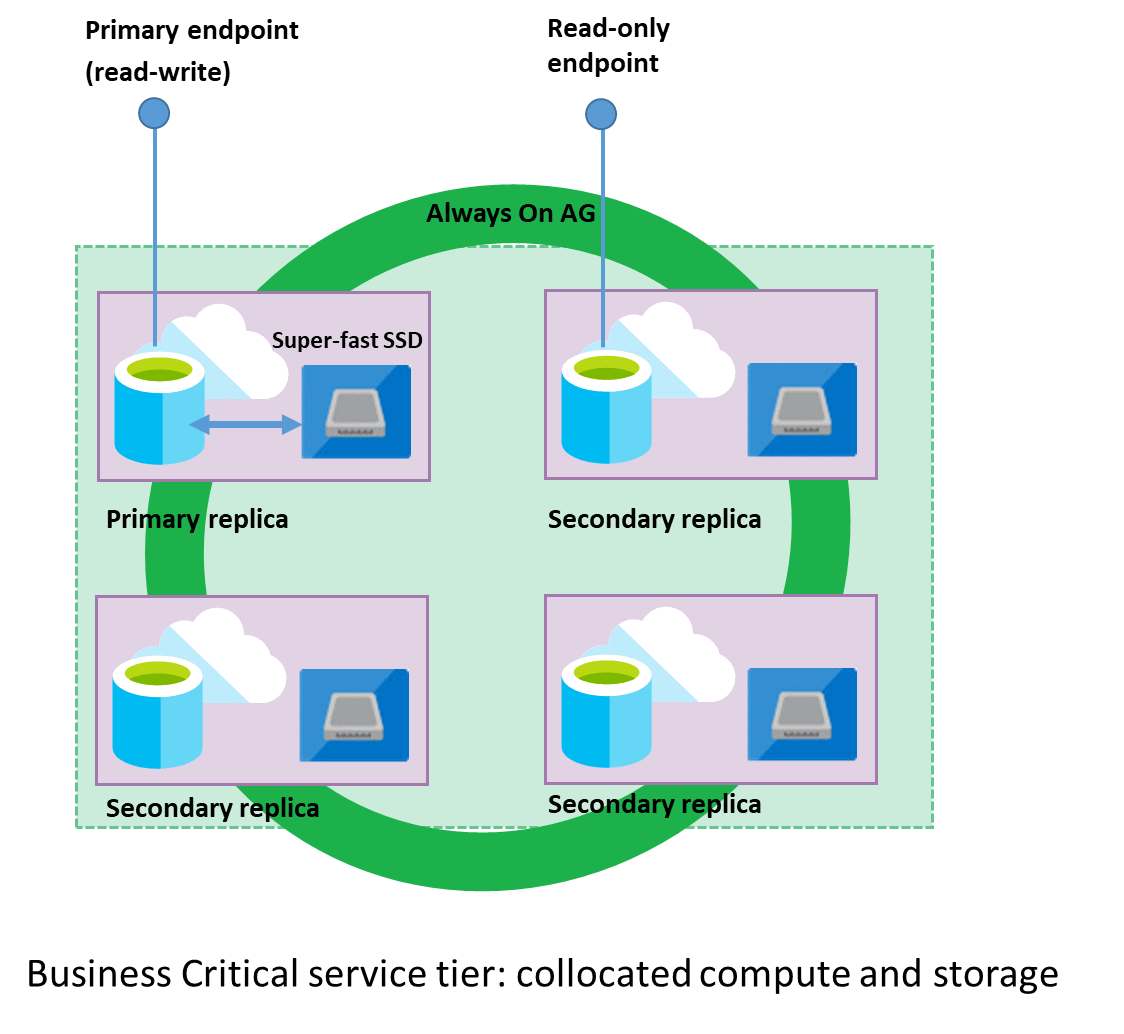
Díky této architektuře je model vhodný pro systémy vyžadující vysokou dostupnost, minimální odezvu, odolnost a velmi časté a náročné dotazování. Nyní se koukneme na jeho nastavení. Pokud jste však pečlivě tento článek četli, tak všechny možnosti již budete perfektně znát.
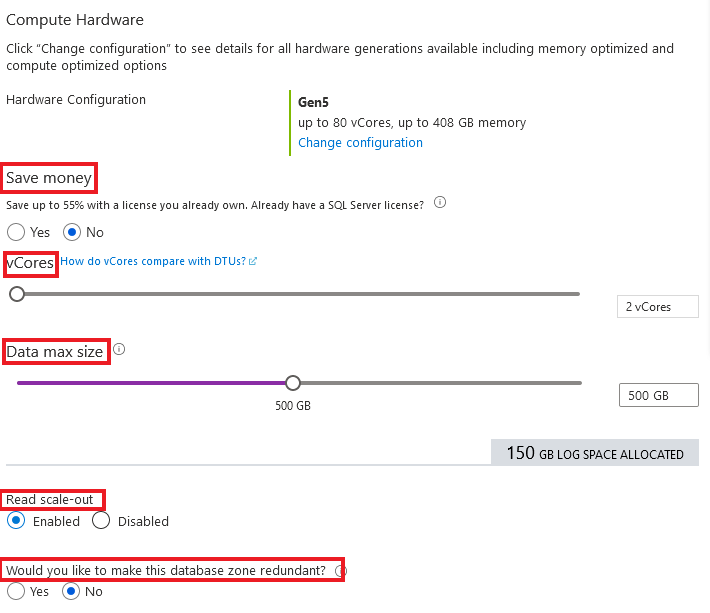
První možností je Save money a díky ní můžete za server ušetřit, pokud již vlastníte licenci pro Microsoft SQL Server. Pomocí posuvníku vCores nastavujete počet virtuálních jader pro vaší databázi a pomocí druhého, hned pod ním, Data max size nastavujete úložiště databáze. Read scale-out vám dovolí používat repliky databáze pro čtení z nich. Poslední z možností je opět využití Availability zón pro lepší dostupnost a pro předcházení případné nefunkčnosti daných datacenter.
Druhy hardware
Možná jste si všimli, že jsme celou dobu nevěnovali pozornost jedné možnosti – Hardware configuration. Tuto možnost vlastní každá úroveň vCore-based modelu a proto jsem ho chtěl vysvětlit v odděleném odstavci. V tuto chvíli máte k dispozici 4 generace hardwaru, ale každá je dostupná ve všech úrovních. Pro přístup k tomuto nastavení klikněte na Change configuration v odstavci Change Hardware.
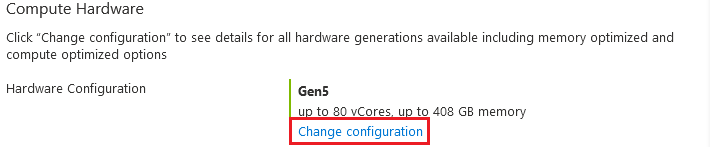
Tyto generace jsou zapsány v tabulce, která obsahuje sloupce společně s jejich výkonem. Můžete v ní zjistit, na co se každá generace hodí ve sloupci Description, maximální možný počet vCores, paměti a úložiště pomocí sloupců Max vCores, Max memory a Max storage. Poslední sloupec Compute cost/vCore/second obsahuje cenu za jedno virtuální jádro za sekundu. Všechny hodnoty zůstávají stejné ve všech úrovních. Mění se pouze jejich cena. Nejlevnější najdete v úrovni General Purpose a nejdražší v Business Critical.

Změna pricing modelu SQL databáze
Poslední věc, kterou vám v tomto článku ukážeme, je změna pricing modelu již existující databáze. Nároky na vaší databázi se můžou neustále měnit, proto společně s tím musíte její výkon upravovat a měnit. Jakmile se dostanete na domovskou stránku vaší databáze, stačí si na levé liště najít kolonku Compute + storage. Po jejím stisknutí se vám otevře stejné menu s pricing modely a úrovněmi, jako jste používali při jejím vytvářením. Nyní můžete libovolně váš pricing změnit a změny aplikujete pomocí tlačítka Apply pod formulářem.
Závěr
Nyní byste měli mít dost dobrou představu mezi rozdíly všech pricing modelů, které momentálně Azure SQL Database nabízí. Jak jste sami viděli, možností je zde mnoho. Díky pochopení těchto úrovní si můžete nastavit databázi přesně vám na míru. Navíc pokud by vám vaše nastavení nevyhovovalo, tak ho vždy můžete změnit, ledaže používáte úroveň Hyperscale. Pro hlubší pochopení pricing modelů SQL databáze nebo zjištění novinek doporučuji zkouknout dokumentaci pro Azure SQL Database. Stay curious!
Přečtěte si i předchozí díl o tom, jak SQL databázi založit.
