V předchozím článku jsme se dozvěděli, co to je Machine Learning Studio, seznámili jsme se s prostředím a vytvořili si základní model experimentu. Služba Azure Machine Leraning Studio ale umí daleko více. Pojďme si projít nějaké další základy, abychom se stali odborníky na strojové učení.
K získání základních znalostí použijeme již připravené modely. Po nich vždy bude následovat procvičení práce a řešení cvičení. Tak pojďme na to!
Práce s UCI knihovnami
V této kapitole si ukážeme, jak implementovat data z webového serveru, přiřadit názvy jednotlivým sloupcům, přezkoumat data a vytvořit základní statistiky.
Výklad
Vytvoření experimentu
Spustíme si naše Microsoft Azure Machine Learning Studio (dále jen MLS), přihlásíme se a založíme nový experiment z šablon Microsoftu nesoucí název „Sample 1: Download dataset…„
EXPERIMENTS -> NEW -> EXPERIMENT -> SAMPLE 1 -> OPEN IN STUDIO

Nyní se nám otevřel již hotový experiment. Pojďme si projít jeho jednotlivé části…
Import Data
Tato položka nám importuje dataset z webové stránky ve formátu CSV.
Enter Data Manually
V této položce nastavujeme manuálně názvy jednotlivým sloupcům. Nesmíme zapomenout opět nastavit správný formát a jako první název přiřadit colum_name. To kvůli návaznosti v R / Python scriptu.
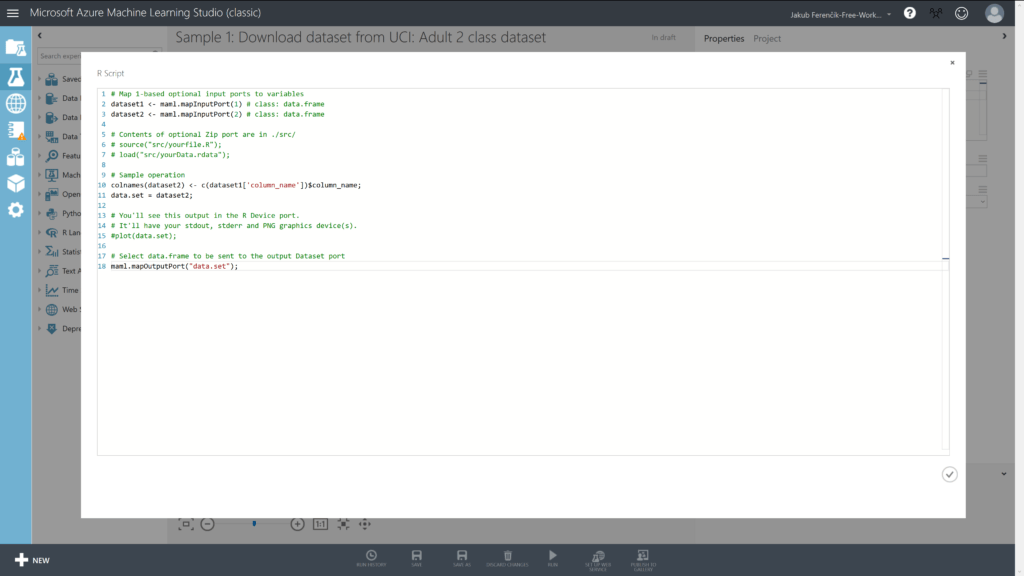
Execute R Script / Python Script
Položka s R Scriptem zajišťuje vytvoření názvů sloupců. Pojďme se podrobněji podívat na kód.
# Do následujících dvou proměnných nadefinujeme, ze kterých portů dostaneme data
dataset1 <- maml.mapInputPort(1) # class: data.frame
dataset2 <- maml.mapInputPort(2) # class: data.framea
# Přejmenujeme sloupce v datasetu 2 na ty, které jsme zadali v datasetu 1
colnames(dataset2) <- c(dataset1['column_name'])$column_name;
data.set = dataset2;
# Data pošleme na výstup
maml.mapOutputPort("data.set");
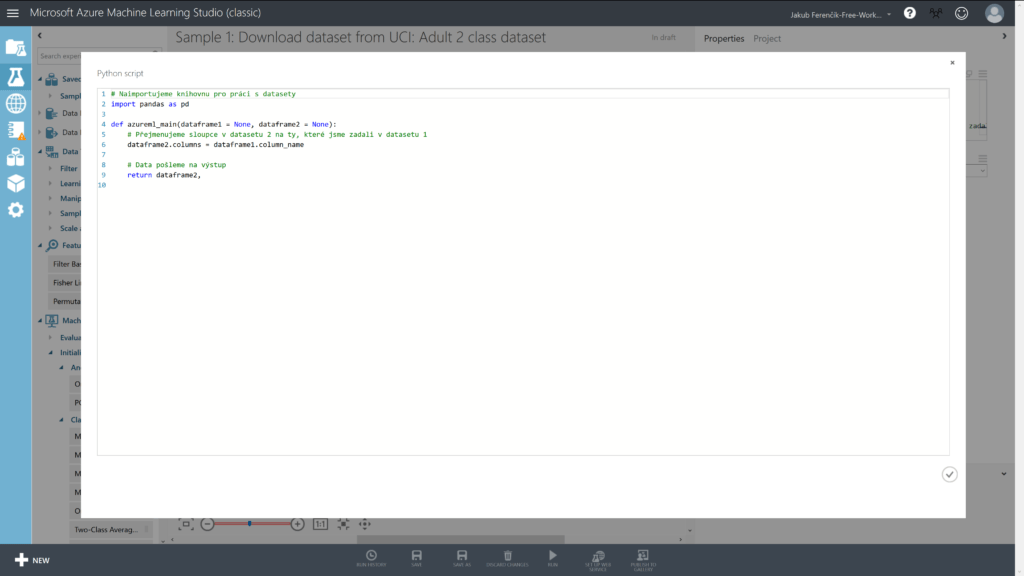
R Script můžeme také nahradit za Python Script. Kód bude pak vypadat následovně:
# Naimportujeme knihovnu pro práci s datasety
import pandas as pd
def azureml_main(dataframe1 = None, dataframe2 = None):
# Přejmenujeme sloupce v datasetu 2 na ty, které jsme zadali v datasetu 1
dataframe2.columns = dataframe1.column_name
# Data pošleme na výstup
return dataframe2,
Summarize Data
Položka, která je schopna vytvořit základní statistiky o daných datech a zobrazit názvy sloupců v tabulce.
Práce s experimentem
Nyní již stačí experiment jednoduše spustit pomocí tlačítka RUN. Jakmile bude celý proces dokončený, stačí, abychom klikli pravým tlačítkem na položku Summarize Data > Result dataset > Visualise a můžeme si zobrazit základní statistiky a celkovou tabulku s názvy sloupců.

Výsledná síť může vypadat třeba takto (POZN. stačí vám pouze jeden typ skriptu, vyberte si ten, který vám vyhovuje více):
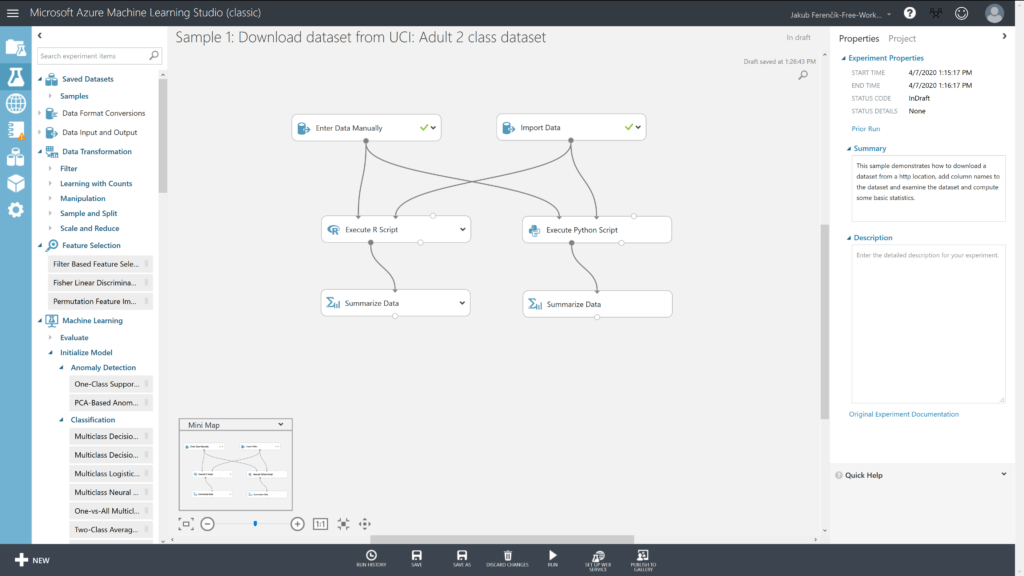
Úkol na procvičení
Do nového experimentu naimportujte data z této adresy (http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data). Vytvořte názvy sloupců a vytvořte jednoduchou analýzu dat.
Informace k datům naleznete zde: http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.names . Využijte k získání názvů jednotlivých sloupců.
Řešení úkolu
Řešení projektu naleznete v Azure AI Gallery na adrese: https://gallery.cortanaintelligence.com/Experiment/STC-Learn-Project-01
Závěr
Práce s daty v Azure není obtížná. Díky grafickému rozhraní se v MLS dokáže orientovat téměř každý. Pro vaše sebevzdělávání je výhodné využívat veřejných knihoven s velikým množstvím dat. Příkladem takové knihovny nám může být například https://data.world/uci nebo https://archive.ics.uci.edu/ml/index.php.