Chtěli byste si ověřovat svoji identitu pomocí vašeho hlasu? Před pár lety se to mohlo zdát jako sci-fi, dnes je to realita. Podívejte se na tento článek a zjistěte, co všechno Speaker Recognition, jedna ze služeb Azure – Speech services, umí.
Obsah
Co je služba Speaker Recognition
Speaker Recognition dokáže identifikovat a ověřit mluvčího podle jeho jedinečných hlasových charakteristik – pomocí hlasové biometrie.
Jak funguje identifikace mluvčího?
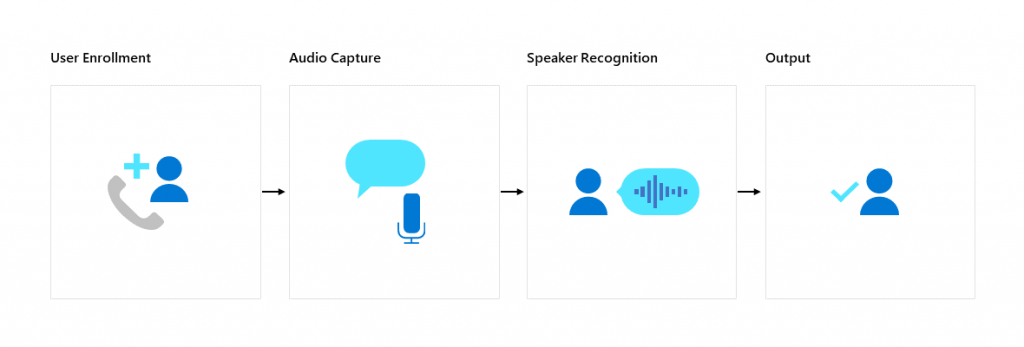
Identifikace mluvčího slouží k určení identity neznámého mluvčího ve skupině lidí a umožňuje přiřadit řeč jednotlivým mluvčím v dané skupině. Při registraci mluvčího dochází k nahrávání hlasu a extrahování jedinečných hlasových prvků, které jsou potřebné k vytvoření hlasového zápisu. Registrace je nezávislá na textu, tudíž mluvčí může říkat cokoliv.
Ve fázi identifikace porovná služba vstupní hlas mluvčího se seznamem zapsaných mluvčích. Speaker Recognition najde nejvíce podobný hlasový záznam a pak ještě pět dalších s podobným skóre v rozsahu od 0 do 1. Pokud žádný z registrovaných zápisů nemá skóre větší nebo rovno 0,5, vrátí se odpověď 0, ,,nebyla nalezena žádná shoda.“
Limity zvukového záznamu:
- maximální délka je 120 sekund
- maximálně 50 mluvčích
- SNshoda schodaR 2dB
Jak funguje ověření mluvčího?
Ověření mluvčího zjednodušuje proces ověřování identity u jednotlivců – a buď na textu závisí anebo na textu nezávisí.
Ověření závislé na textu
Při tomto ověřování si mluvčí zvolí specifickou frázi, kterou speaker recognition použije během registrace i během ověřování. Při registraci mluvčího se extrahují hlasové prvky a zároveň je také zvolená přístupová fráze, aby vytvořily jedinečný hlasový zápis. K ověření se používá hlasový podpis společně s přístupovou frází. Když dochází k ověřování mluvčího, záznam hlasu se pošle do rozhraní API, kde se porovná hlas a fráze se zaregistrovaným profilem mluvčího. Vrátí se výsledek v rozsahu 0 – 1, který určuje, jestli byl kandidát přijat, nebo byl zamítnut. Hodnota vetší nebo rovna 0,5 znamená, že mluvčí je přijat.
V aktuální verzi rozhrání API poskytují 10 anglických frází, které si můžete vybrat pro ověření mluvčího. Můžete si také ale vytvořit vlastní přístupová hesla odesláním požadavků do rozhraní API pro ověření závislé na textu.
Limity zvukového záznamu:
- maximální délka – 10 sekund
- minimální počet nahrávek pro registraci – 3 nahrávky
- maximální počet nahrávek pro registraci – 50 nahrávek
- pro registraci minimální SNR 2dB
- pro ověření minimální SNR 10dB
Ověření nezávislé na textu
Ověření nezávislé na textu se od druhého ověření liší tím, že nemá žádné omezení ohledně toho, co mluvčí říká během zápisu a ověřování hlasové ukázky. Pouze extrahuje hlasové prvky – stejně jako u identifikace mluvčího. Při ověření se porovná hlasová ukázka se zaregistrovaným profilem mluvčího a vrátí se výsledek v rozsahu od 0 do 1, který rozhodne o přijetí nebo nepřijetí mluvčího. Toto ověření se používá k určování zvuku, jestli pochází od živé osoby, nebo je to imitace přihlášeného řečníka.
Limity zvukového záznamu:
- maximální délka je 120 sekund
- minimální SNR 2dB
Použití služby Speaker Recognition
Speaker Recognition zle využít například u ověřování zákazníků call centra, na přepis schůzek, na personalizaci zařízení pro více uživatelů atd.
Vytvoření Speaker Recognition
K vytvoření Speaker recognition potřebujete:
Upozornění: Speaker recognition aktuálně podporují pouze oblasti „WestUS“.
Závěr
Snad vás služba Speaker Recognition zaujala a budete si ji chtít sami vyzkoušet. Existují také další služby Speech, které si můžete vyzkoušet a které by se vám mohly hodit na zmodernizovaní a vylepšení vašich aplikací. Také by vás mohl zajímat náš článek ,,Speech to text v praxi.“