V minulém díle jsme si ukázali knihovny, ze kterých je možné importovat data a jak přiřadit názvy k jednotlivým sloupcům. Dnes se v rámci tohoto seriálu pustíme do editace metadat, nahrazení chybějících dat, vypočítání jednoduché statistiky a vyhodnocení pravděpodobnostní funkce a lineárních korelačních modulů.
TIP: Nezapomeňte, že po výkladové části následuje úkol na procvičení a následné řešení ke kontrole.
Práce s metadaty
V této kapitole si ukážeme, jak editovat metadata, nahrazovat chybějící data, vypočítávat jednoduché statistiky a vyhodnocovat pravděpodobnost funkcí a lineárních korelačních modulů.
Výklad
Vytvoření experimentu
Spustíme si naše Microsoft Azure Machine Learning Studio (dále jen MLS), přihlásíme se a založíme nový experiment z šablon Microsoftu nesoucí název „Sample 2: Dataset Processing and Analysis„.
EXPERIMENTS -> NEW -> EXPERIMENT -> SAMPLE 2 -> OPEN IN STUDIO
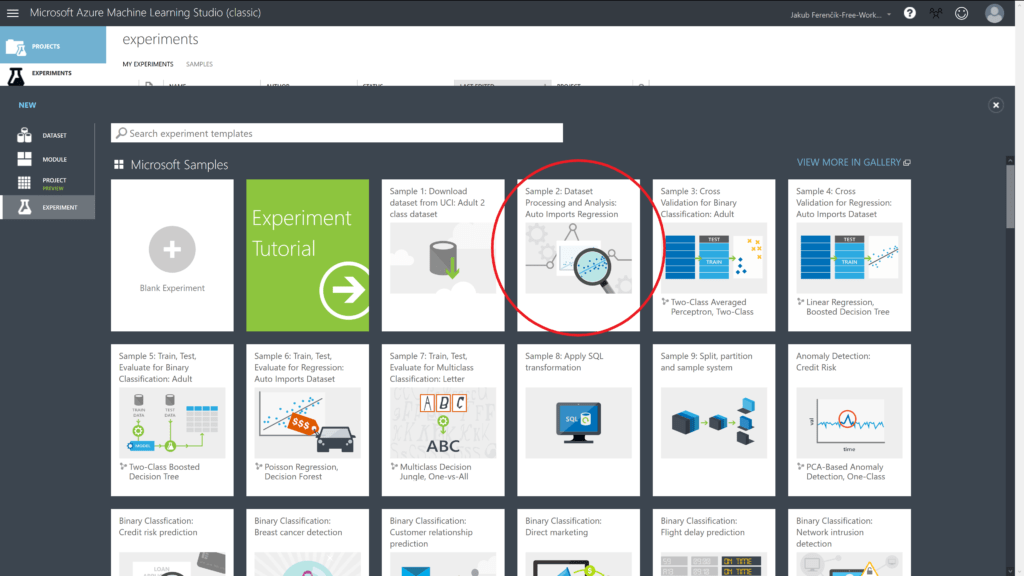
Nyní se nám otevřel již hotový experiment. Pojďme si projít jeho jednotlivé části.
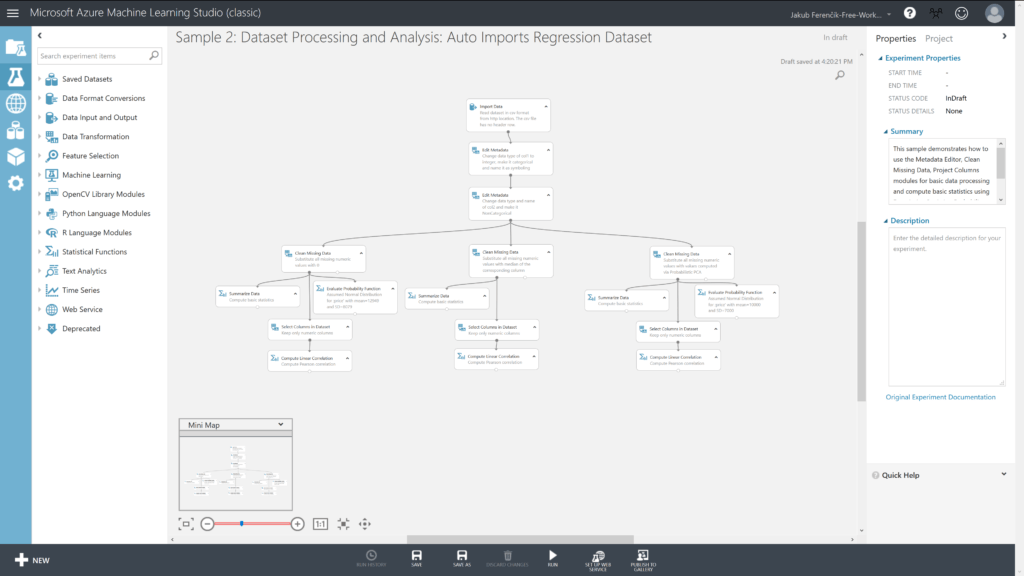
Import Data
Tento blok importuje data z webového serveru ve formátu CSV.
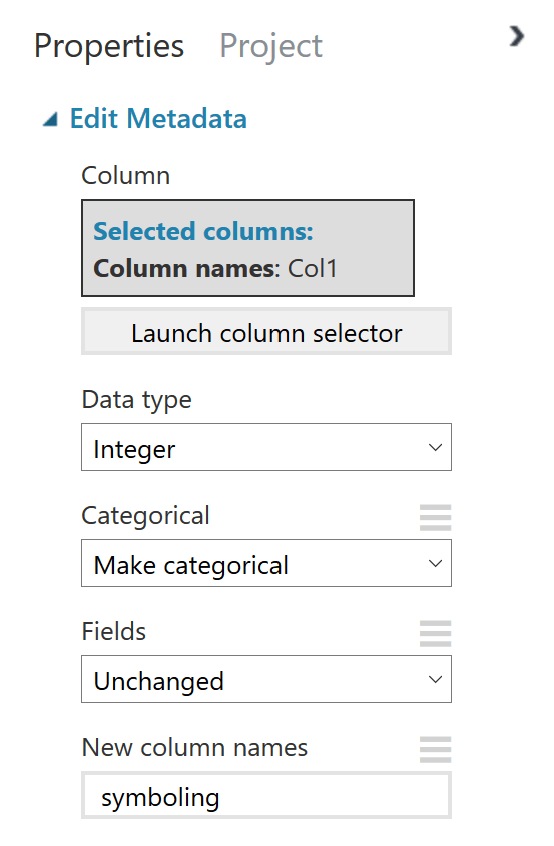
Edit Metadata #1
Upravuje metadata v námi zvoleném sloupci, tedy prvním. Nezapomeňte správně vyplnit následující možnosti:
- Data type – určuje datový typ sloupce
- Categorical – rozhoduje, zdali bude vytvořena kategorie či ne
- Fields – rozhoduje o stavu pole
- New column names – vytvoří nové jméno sloupci
TIP: Podrobnosti o bloku upravující metadata najdeme na: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/edit-metadata
Edit Metadata #2
Má totožné možnosti výběru nastavení jako předchozí blok. Na této si ale můžeme navíc ukázat, jak jde nastavit více sloupců najednou.
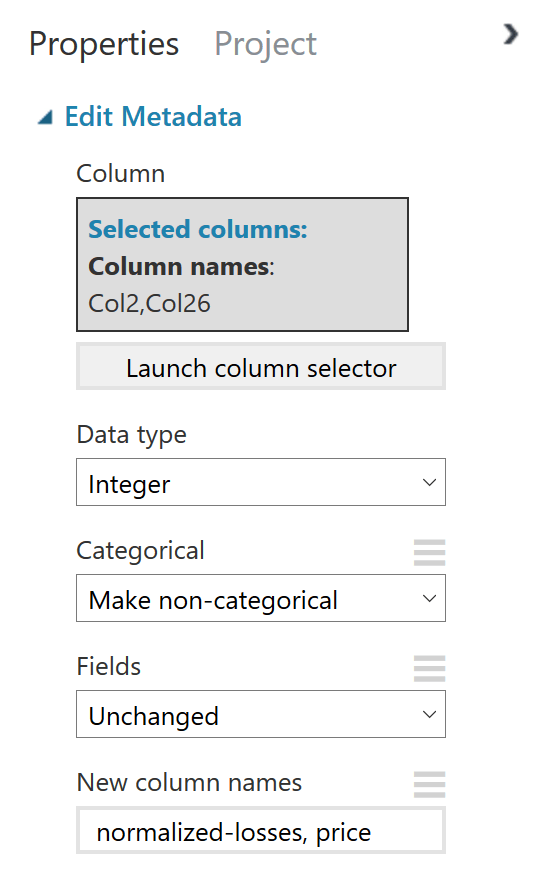
Nyní se dostáváme k rozdělení na tři různé větve, pojďme se nejprve podívat doleva.
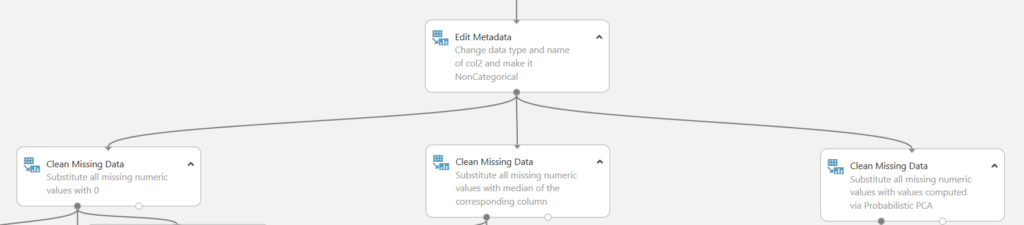
Levá větev
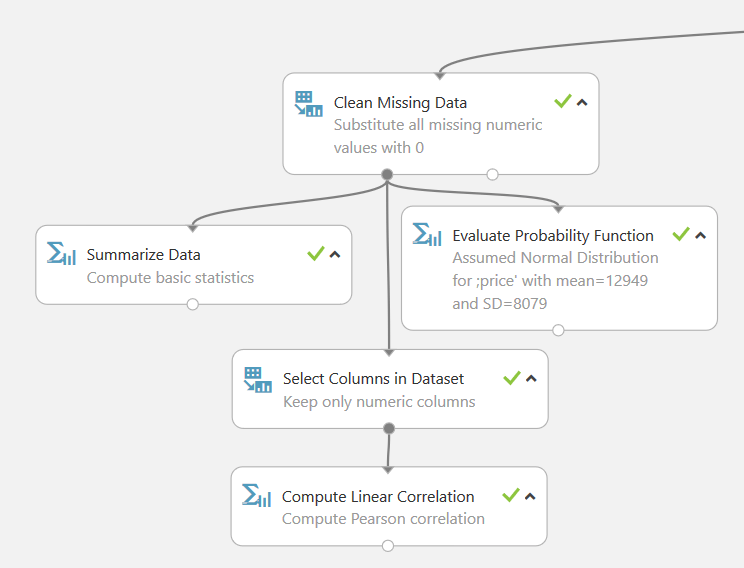
V této větvi se data nejprve vyčistí tak, že se vše chybějící nahradí hodnotou 0. Poté máme možnost zobrazení základní statistiky (Summarize Data) či vyhodnotit pravděpodobnost u sloupce prise (Evalute Probability Function) či lineární korelace (Compute Linear Correlation).
Korelace znamená vzájemný vztah mezi dvěma procesy nebo veličinami. Pokud se jedna z nich mění, mění se korelativně i druhá a naopak.
Prostřední větev
V druhé větvi se data opět nejprve vyčistí, avšak jiným systémem než minule. Zde jsou chybějící data nahrazena mediánem (střední hodnotou) daného sloupce. Následně se opět z dat vytvoří lineární korelace.
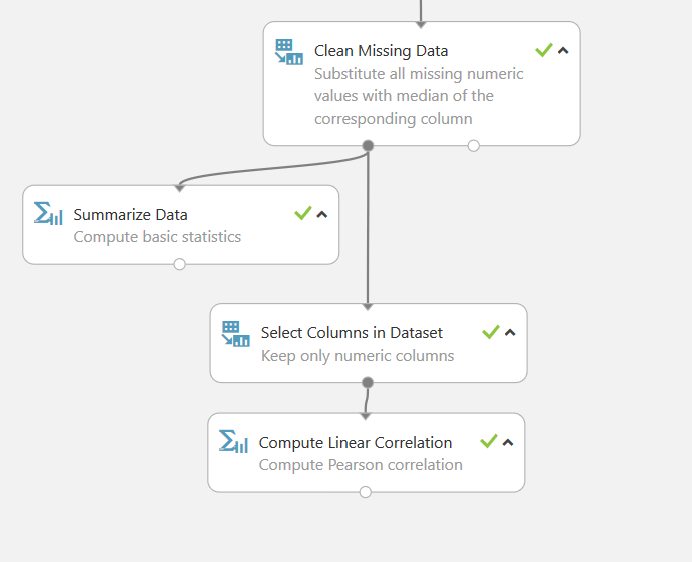
Pravá větev
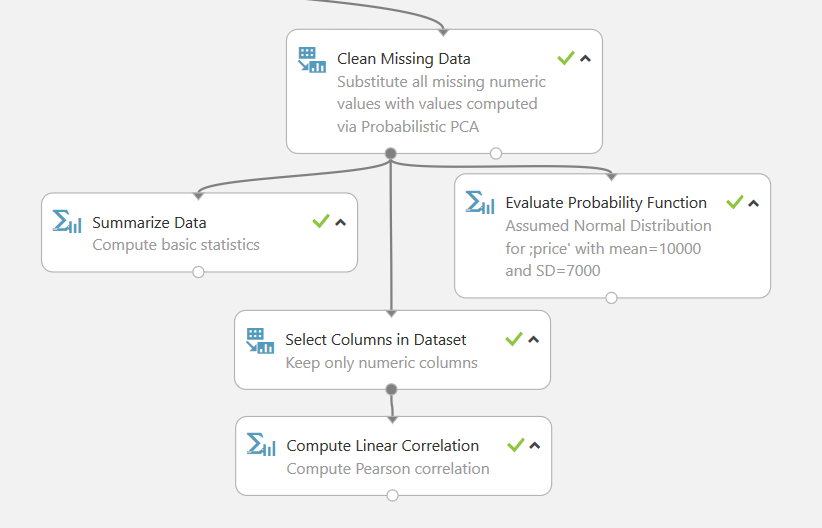
V poslední větvi se nám data vyčistí opět dle jiného klíče než u předchozích větví. Je zde použito tzv. Probability PCA metody. Následně se opět vytvoří jednoduchá lineární korelace.
Probability PCA metoda je technika používaná v případech, kdy potřebujeme doplnit nějaká chybějící data pomocí pravděpodobností.
Práce s experimentem
Nezapomeňte si celý experiment spustit pomocí tlačítka RUN a prohlédnout si výsledky v jednotlivých zobrazovacích blocích.
Úkol na procvičení
Do nového experimentu naimportujte data z této adresy (https://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/processed.cleveland.data). Vytvořte názvy sloupců (ty naleznete zde: https://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/heart-disease.names). Data vyčistěte minimálně třemi způsoby a zobrazte si je v lineární korelaci.
Řešení úkolu
Řešení projektu naleznete v Azure AI Gallery na adrese: https://gallery.azure.ai/Experiment/STC-Learn-Project-02
Závěr
Vyčištění dat je v Azure je velice efektivní. Azure za vás dokáže sám dopočítat chybějící nejpravděpodobnější údaje pomocí spousty algoritmů. Stačí jen vybrat ten pravý.