V minulém díle jsme se podívali na to, jak se vypořádat s chybějícími daty v datasetu, použili pravděpodobnostní funkci a naučili se upravovat metadata. Tentokrát se již začneme věnovat umělé inteligenci a vytrénujeme si první model.
Ti všímavější si jistě říkali, proč se tato série jmenuje „Umělá inteligence,“ když se ji v článcích nevěnujeme. Důvod je takový, že je nutné předem vědět, jak Azure Machine Learning Studio používat. Proto, pokud jste předchozí díly neviděli, doporučuji si je projít před pokračováním.
Úvod
Náplní experimentu v tomto článku bude predikce ceny automobil podle některých parametrů (např. typ paliva – benzín / nafta, lokace motoru – vpředu / vzadu, rozměrech, maximálních otáčkách motoru, a mnoha dalších).
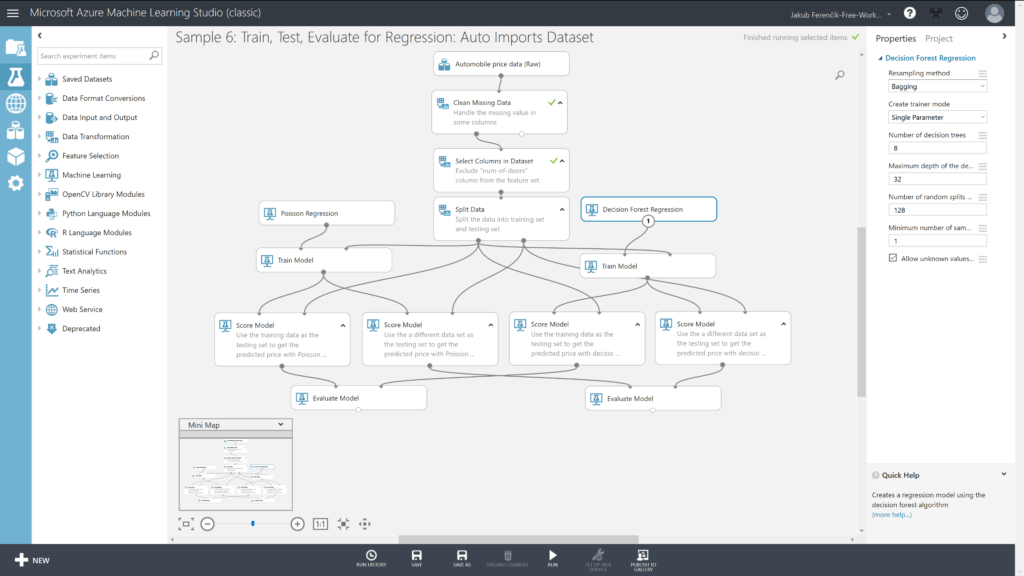
Budeme využívat předpřipravený experiment „Sample 6: Train, Test, Evaluate for Regression: Auto Imports Dataset“.
Teorie
Budeme se věnovat dvěma procesům AI – tréninku (training) a vyhodnocení (evaluation). Netřeba se však bát, jelikož díky MLS se ke kódu ani složité matematice nedostaneme.
Trénink
Pro trénink potřebujeme dataset, který obsahuje všechny informace a hodnoty včetně té, kterou budeme chtít předpovídat (v tomto případě cenu). Při něm si AI vytvoří souvislosti a zjistí, jak moc závisí cena na všech jednotlivých parametrech automobilů.
Vyhodnocení
Druhou fází je vyhodnocení správnosti naší AI, ke které budeme potřebovat také dataset s kompletními daty. Během postupně vyzkouší, jak přesná naše AI je. Funguje to tak, že se pomocí modelu predikuje cena na základě vstupních parametrů (tedy všech parametrů až na cenu) a posléze tuto predikovanou hodnotu porovnáme s hodnotou v datasetu a vypočítáme tzv. odchylku (tedy nějaké procento, jak moc se ceny liší).
Nové bloky
Na obrázku výše jste si mohli všimnout, že nám také přibylo několik nových bloků, pojďme se na ně podívat podrobněji…
Split Data
Blok Split Data nám jeden vstupní dataset rozdělí na dva (jeden pro trénink a druhý pro vyhodnocení), abychom jich nemuseli importovat více. Ve vlastnostech bloku si můžeme nastavit, v jakém poměru se data rozdělí – já použiji výchozí nastavení 60 % a 40 %.
Train Model
V tomto bloku začíná ta pravá „magie“ – trénink.
Jsou zde dva vstupy – nevycvičený model a data. S nimi proběhne algoritmus, který nevycvičený model vycvičí, abychom ho byli schopni použít pro predikci.
Jako data zvolíme první výstup z bloku Split Data (tedy naše tréninková data) a nevycvičený model získáme pomocí některého bloku regrese – Poisson Regression je typ lineární regrese a Decision Forest Regression si představte jako několik rozhodovacích stromů.
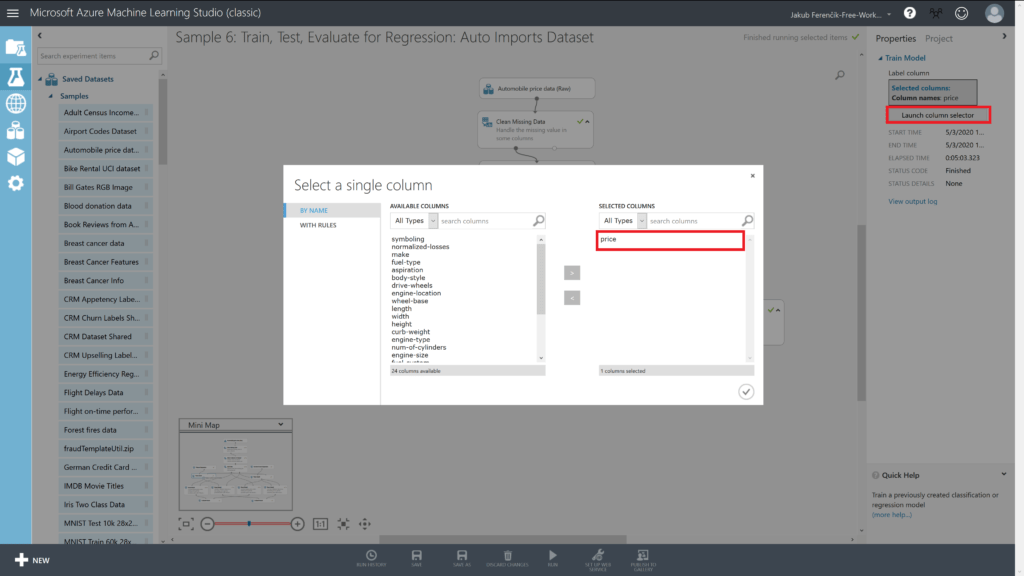
Ve vlastnostech bloku můžeme zvolit, které parametry chceme později predikovat.
Score Model
Tento blok slouží pro vyhodnocení, tedy pro predikci cen. První vstup – vycvičený model – získáme jako výstup z bloku Train Model a druhý vstup tvoří opět data automobilů, u kterých chceme cenu predikovat.
Výstupem je nový dataset, který obsahuje sloupec Scored Labels, což jsou predikované ceny.
Evaluate Model
Vstupem jsou dva vyhodnocené datasety, které dostaneme jako výstup dvou bloků Score Model.
Výstupem je porovnání a informace o přesnosti našeho vycvičeného modelu.
Výsledek
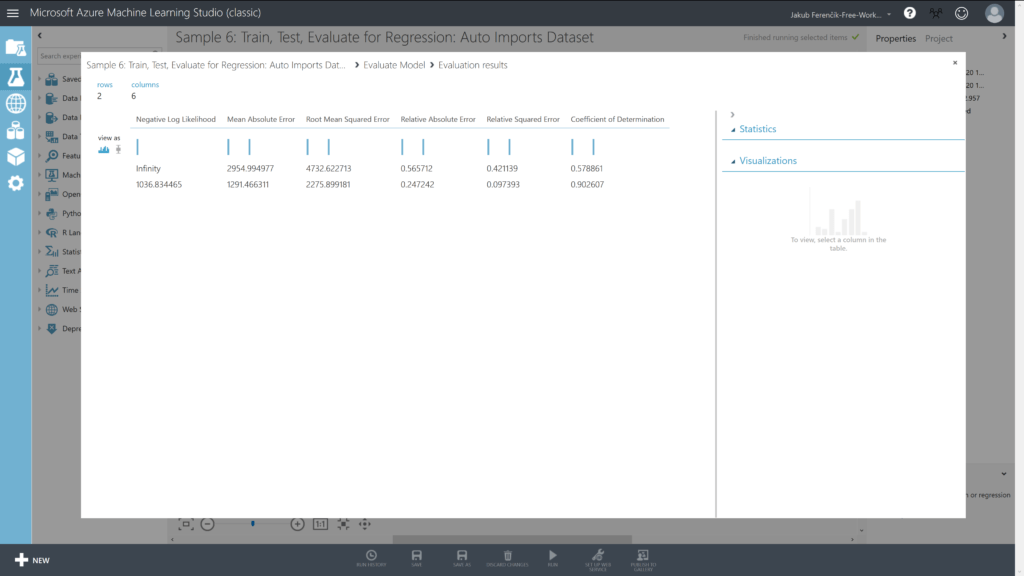
Veškerá práce je nyní hotová a my můžeme experiment spustit. Po úspěšném dokončení otevřeme reprezentaci dat pro jeden libovolný blok Score Model a podíváme se na predikované ceny – níže je výsledek z bloku, který má jako vstup první Train Model (vycvičený pomocí Poissnovy regrese) a druhou část dat (testovací).
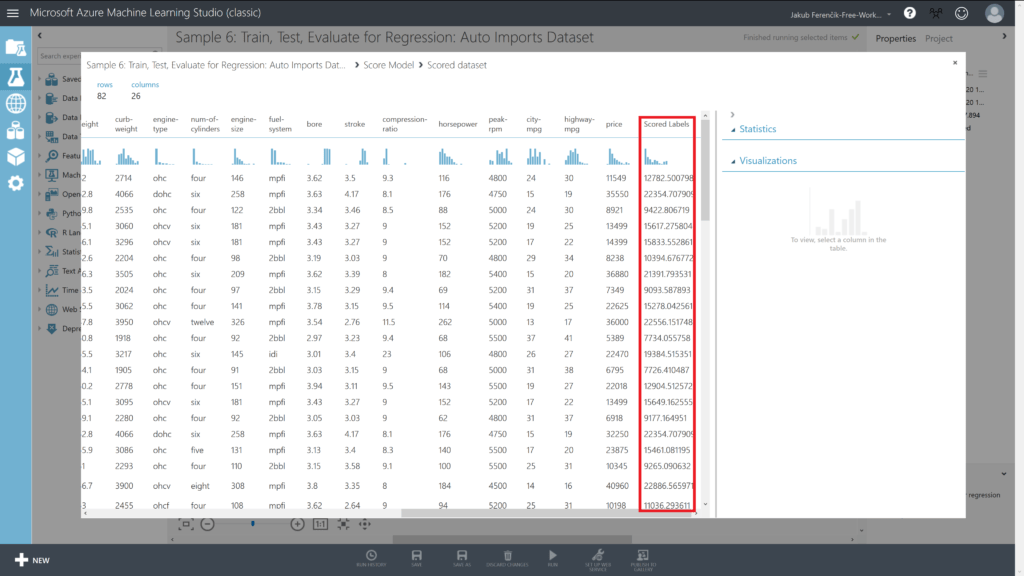
Vidíme, že výsledky jsou relativně podobné, jako ceny zadané, přesto se zde objevují i výjimky, kde to uskočí o větší část. To dokazuje, že AI není perfektní, avšak přesnost můžeme zvýšit zvolením jiných postupů pro trénování.
Ve vizualizaci bloku Evaluate Model nalezneme různé typy odchylek. Pro nás bude nejzajímavější Mean Absolute Error (střední absolutní odchylka) – ta vyjadřuje průměrný absolutní rozdíl mezi predikovanou a reálnou cenou. Bude nás také zajímat tzv. Coefficient of Determination (koeficient determinace), který nám udává, jak přesná naše AI je.
Export vycvičeného modelu
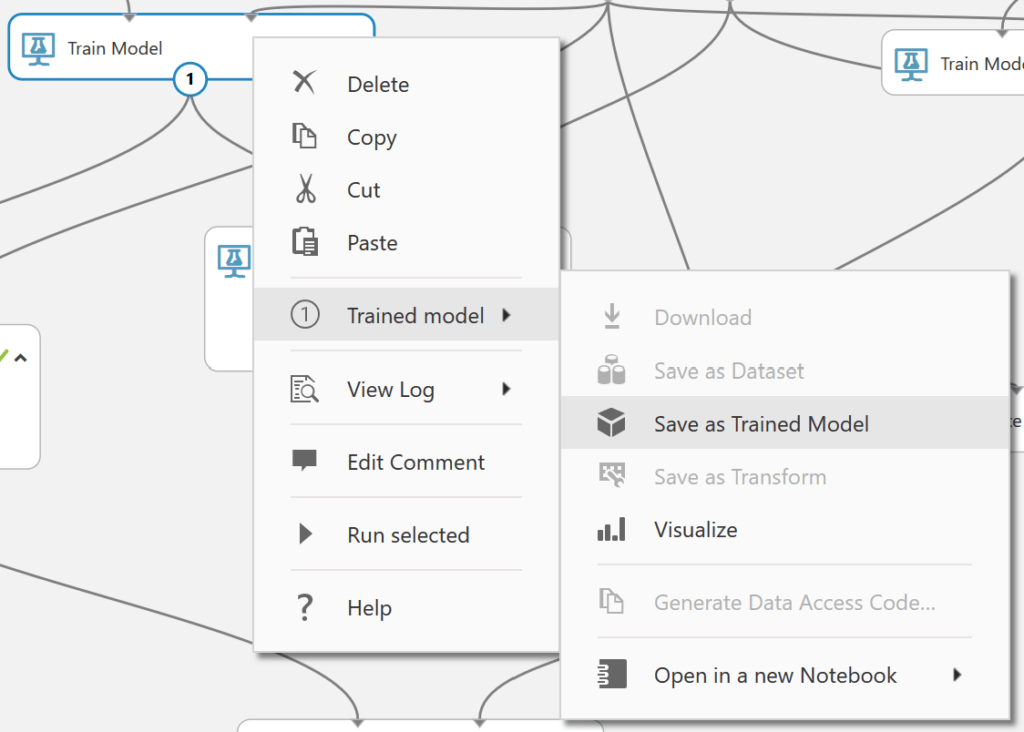
Pokud chceme vycvičený model uložit pro použití později v jiných experimentech / projektech, můžeme si ho uložit mezi tzv. Trained models (viz 2. díl série).
Vybereme si libovolný blok Train Model a otevřeme kontextovou nabídku pomocí pravého kliknutí a v podnabídce Trained Model stiskneme Save as Trained Model. Objeví se dialogové okno, kde si můžeme model pojmenovat.
Po úspěšném uložení se nám model objeví v sekci Trained Models a také mezi bloky v editoru.
Závěr
V tomto článku se objevilo mnoho nových a relativně složitých souvislostí. Pokud jste je napoprvé všechny nepobrali, nezoufejte, zkuste si článek přečíst znovu později. Nebo si můžete pohrát se zapojením a nastavením jednotlivých bloků a sledovat, co se jak mění.